
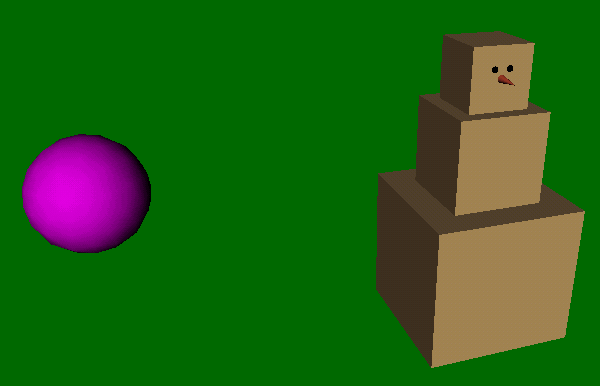
Note: A more complete desciption of the DIVA model is forthcoming:
Croft, D., & Thagard, P. (forthcoming). Dynamic Imagery: a computational model of motion and visual analogy. In L. Magnani (ed.), Model-based reasoning, Kluwer/Plenum, New York.
DIVA is a computer model that attempts to simulate some interesting characteristics of the human mind's mental imagery system. It is based upon a hierarchical organization of visual information called the scene graph - a representation developed by computer graphics researchers to model the 3-dimensional world using a computer.
Mental imagery has been a relatively neglected field of research in cognitive science. It is much more difficult to represent and process visual information on a computer than it is to represent and process text-based information. The reality that needs to be addressed is that much of human thought is based upon visual thinking - our brain has evolved to help us survive in a 3-dimensional world, not an ascii world of text symbols.
The DIVA model does not attempt to simulate the low-level visual representation used by the human mind. What the model hypothesizes is that at some level of abstraction, the human mind breaks apart visual input into discrete pieces (whether they be images or verbal propositions) that can be analyzed and recombined to create any number of visual scenes. For example, we are able to extract visual concepts such as "dog" and "mars", and combine these to create a scene containing a dog on mars. Furthermore, we can break apart visual concepts such as "dog" and identify components such as "leg" or "head". The scene graph provides an organizational structure to relate individual objects such as "leg" and "head" to a larger whole such as "dog".
It is the discrete nature of mental imagery and our ability to analyze visual concepts at different levels of detail that serves as the basis of the DIVA model. The scene graph simply serves as a computational representation of the discrete and recombinant nature of visual thinking.
The DIVA computer model was developed with the Java programming language and a scene-graph based programming library called Java3D. Using the scene graph as the basic representation, the DIVA model has algorithms to establish analogical mappings between visual scenes. These algorithms are based upon a constraint-satisfaction approach used for mapping verbal representations in the program ACME (Holyoak and Thagard, 1989).
What similarities are immediately noticeable when viewing the two pictures below?
We notice that the left scene contains an object that resembles a snowman, and a similar figure, but made from blocks, is in the right scene. Also, both scenes contain a purple object off to the side, although one is a box while the other is a sphere.
The above two scenes are represented in the DIVA model using Java3D scene graphs. Based upon the structure of the scene graph and the properties of individual pieces within each graph, a network of potential mappings is established in the memory of the model. A connectionist algorithm is then used to settle the network and find the most prominent mappings. It is important to note that it is structural associations defined by the scene graph that determine how the network will settle. The output of the visual similarity algorithm for the snowman and blockman scenes is shown below:
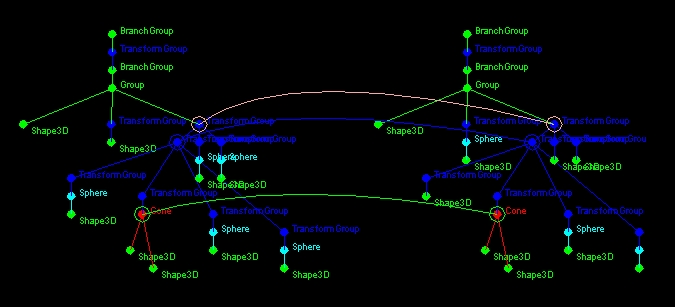
Above: the strongest mappings (drawn as arcs) between nodes of the two graphs demonstrate DIVA's ability to recognize structural wholes. For example, the top arc in the figure represents the mapping between the snowman and the blockman - prominent even though the two objects are composed of different shapes in slightly different positions. The middle arc represents the mapping between the heads of the two figures - although the heads are different shapes, they are composed with the same carrot-nose and coal-eyes, and are in the same context relative to their respective wholes. The bottom-most arc is between the two noses - they are the same shape and color, and are in the same position relative to the head objects.
The strength of DIVA's visual similarity algorithm is that is considers how each discrete object (eg. head, nose) is connected within a larger whole. Note that there is no prominent mapping between the middle ball of the snowman and the "distractor" sphere object in the scene with the blockman. Although a mapping is established between the purple box on the left and the purple box on the right, after settling the network, this mapping was not as prominent as the three described above. Is this realistic? The two purple objects definitely stand out, but they do so because they are different! Differences are an important aspect of analogies that need to be considered in the model - maybe in a future release...
The dimension of time is a critical component of our mental imagery system - it enables us to imagine and solve problems about things that move. Motion is another discrete property of our visual thoughts that can be extracted, analyzed and recombined with other visual concepts. For example, we can imagine a cat typing at the computer even though we have probably never perceived this situation.
As another example, think about the expression "it is raining cats and dogs". We are able to extract the motion of falling raindrops and apply these to concepts of "dog" and "cat" to imagine these animals falling from the sky. When we dream, we extract visual objects and animate them into scenarios that we have never observed. Our ability to form these mental movies is based upon our ability to combine static concepts with remembered motion patterns.
One well-cited example of visual analogy in cognitive science literature is the "tumor problem". This is a scenario in which a doctor is trying to destroy the tumor in the brain of a patient. A single intense beam of radiation cannot be used to destroy the tumor because it will also damage the surrounding tissue. Visual analogy comes into play after reading (and imagining) the following story:
A general is trying to invade a fortified castle. If he sends all his troops to the front door, the castle can easily defend itself and the attacking general must admit defeat. After some hard-thinking, the general decides to divide his troops into a number of smaller units, and have them attack from all sides of the castle. Using this tactic, he is successful.
Having been primed by the success of the general, we can construct a visual analogy that provides a solution for the doctor: by using a number of weaker radiation beams arranged around the patient's head, the tumor can be destroyed without damaging the surrounding tissue.
The scene graph used by the DIVA computer model enables dynamic situations to be represented (such as the general attacking the castle) - and to a very limited extent, "reasoned about". You cannot see the soldiers moving (yellow-sphere soldiers) in the image below - internally though DIVA is trying to detect patterns of motion amongst the group of objects:
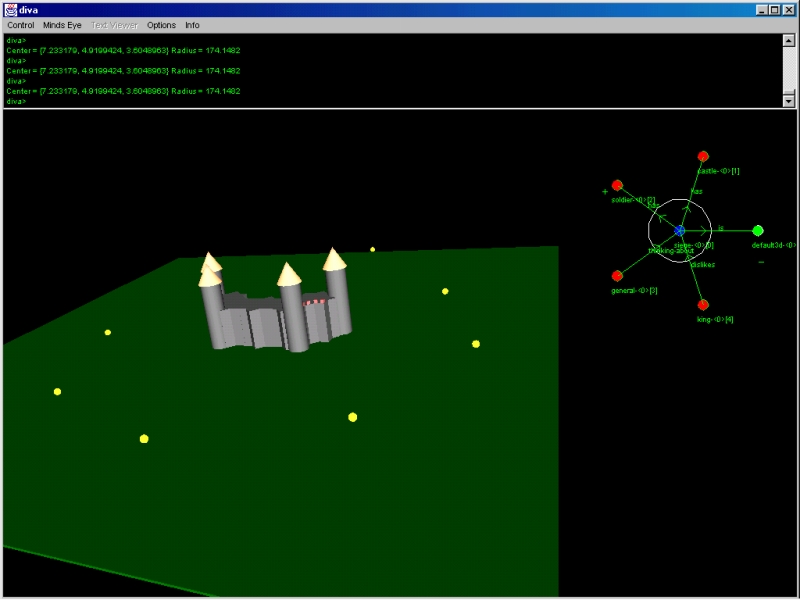
There is a similar pattern of motion between soldiers converging upon a castle and radiation-beams entering the patient's head that helps us to establish an analogy. DIVA's visual similarity algorithm tries to establish whether any motion patterns exist (currently only convergence patterns, however orbital motion and parallel motion are in the works) and then establishes additional mappings between objects that contribute to this motion pattern (eg. a soldier converging upon the castle and a beam directed towards the tumor). For an example of visual analogy based upon orbital motion, think about the similarity between the standard atom model with electrons circling the nucleus, and the concept of our solar system, with planets orbiting the sun.
If you would like to see more examples or experiment with DIVA's visual similarity algorithm, the model can be downloaded and used to generate visual analogies between two VRML models (VRML stands for Virtual Reality Modeling Language, a file-format used to exchange 3-dimensional models on the World Wide Web). I should warn any potential downloaders that this model was developed to experiment with ideas about how we organize and solve problems based upon the structure imposed by 3-dimensions (+time). The model is not even alpha-release quality and lacks thorough documentation (you have to read the source code).
Having been warned, the source code and class files for DIVA are packed into a zip file: diva.zip (~ 840 KB).
The readme file (also contained in the zip file download) discusses system requirements, the procedure for configuring the software, and a quick introduction to using the program. Although DIVA has been developed with the Java language (which is supposed to be cross-platform), it is currently limited to Windows, Solaris and Linux platforms - Java's 3D libraries are not yet supported for MacInstosh.
Note 1: the command-line used in DIVA is out of date with the newest cline package. Additionally, the associative network has been completely rewritten for the symblnet project.
Note 2: a number of VRML files are included in the package - however not all VRML node-types are supported by Java3D's VRML converter and by the DIVA model.
More information about the Java3D scene graph used within the model can be found at: http://java.sun.com/products/java-media/3D/collateral/j3d_api/j3d_api_4.html
My thanks to Paul Thagard for supervising this project and for key ideas about the visual similarity algorithm.